This page highlights several of my research and personal projects. For a complete list of my publications, see my publications page.
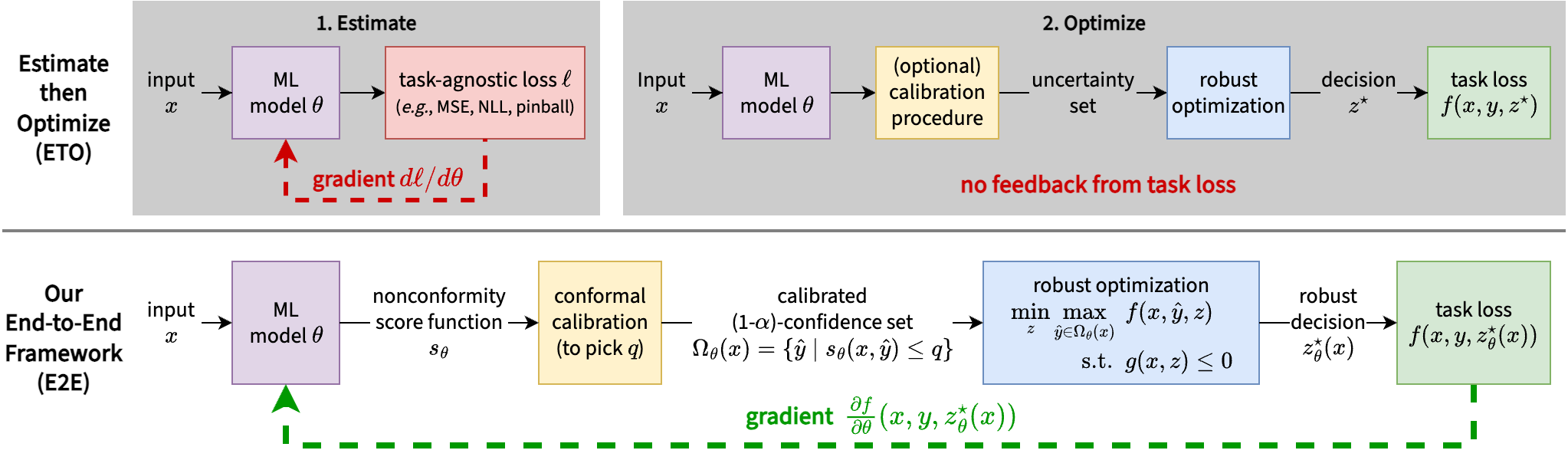
Our end-to-end conformal calibration method learns uncertainty sets for robust optimization that are informed by the downstream decision-making loss, while providing robustness and calibration guarantees from differentiable conformal prediction.
End-to-End Conformal Calibration for Optimization Under Uncertainty
Caltech, 2023 - present
Machine learning can significantly improve performance for decision-making under uncertainty in a wide range of domains. However, ensuring robustness guarantees requires well-calibrated uncertainty estimates, which can be difficult to achieve with neural networks. Moreover, in high-dimensional settings, there may be many valid uncertainty estimates, each with their own performance profile—i.e., not all uncertainty is equally valuable for downstream decision-making. To address this problem, we develop an end-to-end framework to learn uncertainty sets for conditional robust optimization in a way that is informed by the downstream decision-making loss, with robustness and calibration guarantees provided by conformal prediction. In addition, we propose to represent general convex uncertainty sets with partially input-convex neural networks (PICNNs), which are learned as part of our framework. Our approach consistently improves upon two-stage estimate-then-optimize baselines on concrete applications in energy storage arbitrage and portfolio optimization.
Collaborators: Nicolas Christianson, Alan Wu, Adam Wierman, Yisong Yue
Publications:
- End-to-End Conformal Calibration for Optimization Under Uncertainty
C. Yeh*, N. Christianson*, A. Wu, A. Wierman, Y. Yue
Preprint - End-to-end conformal calibration for robust grid-scale battery storage optimization
C. Yeh*, N. Christianson*, A. Wierman, and Y. Yue
NeurIPS 2024 Workshop on Tackling Climate Change with Machine Learning, Dec. 2024 - Decision-aware uncertainty-calibrated deep learning for robust energy system operation
C. Yeh, N. Christianson, S. Low, A. Wierman, and Y. Yue
ICLR 2023 Workshop on Tackling Climate Change with Machine Learning, May 2023
Our end-to-end conformal calibration method learns uncertainty sets for robust optimization that are informed by the downstream decision-making loss, while providing robustness and calibration guarantees from differentiable conformal prediction.

SustainGym: Reinforcement Learning Environments for Sustainable Energy Systems
Caltech, 2022 - 2023
The lack of standardized benchmarks for reinforcement learning (RL) in sustainability applications has made it difficult to both track progress on specific domains and identify bottlenecks for researchers to focus their efforts. In this paper, we present SustainGym, a suite of five environments designed to test the performance of RL algorithms on realistic sustainable energy system tasks, ranging from electric vehicle charging to carbon-aware data center job scheduling. The environments test RL algorithms under realistic distribution shifts as well as in multi-agent settings. We show that standard off-the-shelf RL algorithms leave significant room for improving performance and highlight the challenges ahead for introducing RL to real-world sustainability tasks.
Collaborators: Victor Li, Rajeev Datta, Julio Arroyo Ibarra, Nicolas Christianson, Chi Zhang, Yize Chen, Mohammad Mehdi Hosseini, Azarang Golmohammadi, Yuanyuan Shi, Yisong Yue, Adam Wierman
Publications:
- SustainGym: Reinforcement Learning Environments for Sustainable Energy Systems
C. Yeh, V. Li, R. Datta, J. Arroyo, N. Christianson, C. Zhang, Y. Chen, M. Hosseini, A. Golmohammadi, Y. Shi, Y. Yue, and A. Wierman
NeurIPS 2023 Datasets and Benchmarks Track - SustainGym: A Benchmark Suite of Reinforcement Learning for Sustainability Applications
C. Yeh, V. Li, R. Datta, Y. Yue, and A. Wierman
NeurIPS 2022 Workshop on Tackling Climate Change with Machine Learning
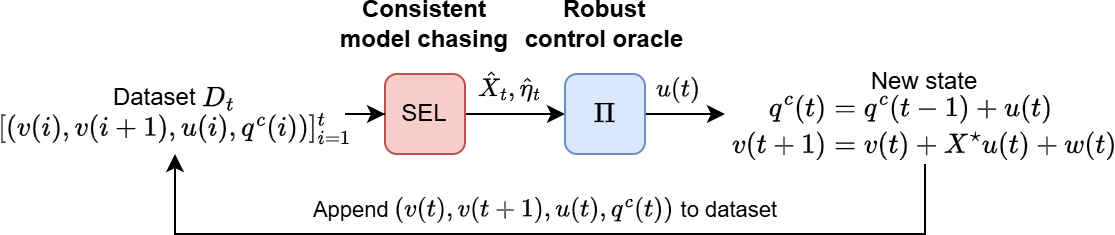
Our voltage control method combines a consistent model chasing algorithm with a robust control oracle to achieve a finite-mistake guarantee even when the distribution grid topology is unknown.
Online learning for robust voltage control under uncertain grid topology
Caltech, 2022 - 2024
Voltage control generally requires accurate information about the grid’s topology in order to guarantee network stability. However, accurate topology identification is challenging for existing methods, especially as the grid is subject to increasingly frequent reconfiguration due to the adoption of renewable energy. In this work, we combine a nested convex body chasing algorithm with a robust predictive controller to achieve provably finite-time convergence to safe voltage limits in the online setting where there is uncertainty in both the network topology as well as load and generation variations. In an online fashion, our algorithm narrows down the set of possible grid models that are consistent with observations and adjusts reactive power generation accordingly to keep voltages within desired safety limits. Our approach can also incorporate existing partial knowledge of the network to improve voltage control performance. We demonstrate the effectiveness of our approach in a case study on a Southern California Edison 56-bus distribution system. Our experiments show that in practical settings, the controller is indeed able to narrow the set of consistent topologies quickly enough to make control decisions that ensure stability in both linearized and realistic non-linear models of the distribution grid.
Collaborators: Jing Yu, Yuanyuan Shi, Adam Wierman
Publications:
- Online learning for robust voltage control under uncertain grid topology
C. Yeh, J. Yu, Y. Shi, A. Wierman
IEEE Transactions on Smart Grid, September 2024 - Robust online voltage control with an unknown grid topology
C. Yeh, J. Yu, Y. Shi, and A. Wierman
ACM e-Energy 2022, Best paper award finalist
Our voltage control method combines a consistent model chasing algorithm with a robust control oracle to achieve a finite-mistake guarantee even when the distribution grid topology is unknown.

SustainBench: Benchmarks for Monitoring the Sustainable Development Goals with Machine Learning
Caltech, 2020 - 2021
Progress toward the United Nations Sustainable Development Goals (SDGs) has been hindered by a lack of data on key environmental and socioeconomic indicators, which historically have come from ground surveys with sparse temporal and spatial coverage. Recent advances in machine learning have made it possible to utilize abundant, frequently-updated, and globally available data, such as from satellites or social media, to provide insights into progress toward SDGs. Despite promising early results, approaches to using such data for SDG measurement thus far have largely evaluated on different datasets or used inconsistent evaluation metrics, making it hard to understand whether performance is improving and where additional research would be most fruitful. Furthermore, processing satellite and ground survey data requires domain knowledge that many in the machine learning community lack. In this paper, we introduce SustainBench, a collection of 15 benchmark tasks across 7 SDGs, including tasks related to economic development, agriculture, health, education, water and sanitation, climate action, and life on land. Datasets for 11 of the 15 tasks are released publicly for the first time. Our goals for SustainBench are to (1) lower the barriers to entry for the machine learning community to contribute to measuring and achieving the SDGs; (2) provide standard benchmarks for evaluating machine learning models on tasks across a variety of SDGs; and (3) encourage the development of novel machine learning methods where improved model performance facilitates progress towards the SDGs.
Mentors: Prof. Stefano Ermon, Prof. Marshall Burke, Prof. David Lobell
Collaborators: Chenlin Meng, Sherrie Wang, Anne Driscoll, Erik Rozi, Patrick Liu, Jihyeon Lee
Publication: SustainBench: Benchmarks for Monitoring the Sustainable Development Goals with Machine Learning
C. Yeh*, C. Meng*, S. Wang*, A. Driscoll, E. Rozi, P. Liu, J. Lee, M. Burke, D. B. Lobell, and S. Ermon
NeurIPS 2021, Datasets and Benchmarks Track (Round 2)
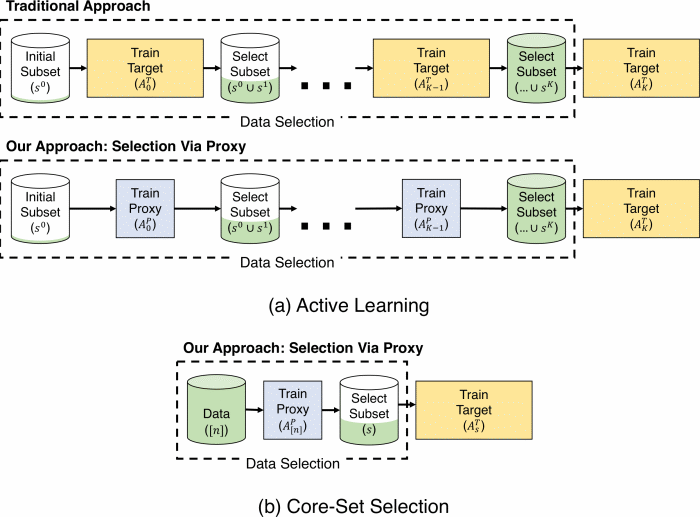
In both active learning and core-set selection settings, our “selection via proxy” approach uses a smaller proxy model to select data for a larger target model.
Selection via Proxy: Efficient Data Selection for Deep Learning
Stanford University, Summer 2018 - 2019
Data selection methods, such as active learning and core-set selection, are useful tools for machine learning on large datasets. However, they can be prohibitively expensive to apply in deep learning because they depend on feature representations that need to be learned. We show that we can greatly improve the computational efficiency by using a small proxy model to perform data selection (e.g., selecting data points to label for active learning). By removing hidden layers from the target model, using smaller architectures, and training for fewer epochs, we create proxies that are an order of magnitude faster to train. Although these small proxy models have higher error rates, we find that they empirically provide useful signals for data selection. We evaluate this “selection via proxy” (SVP) approach on several data selection tasks across five datasets: CIFAR10, CIFAR100, ImageNet, Amazon Review Polarity, and Amazon Review Full. For active learning, applying SVP can give an order of magnitude improvement in data selection runtime (i.e., the time it takes to repeatedly train and select points) without significantly increasing the final error (often within 0.1%). For core-set selection on CIFAR10, proxies that are over 10x faster to train than their larger, more accurate targets can remove up to 50% of the data without harming the final accuracy of the target, leading to a 1.6x end-to-end training time improvement.
Mentors: Prof. Matei Zaharia, Prof. Peter Bailis, Prof. Jure Leskovec, Prof. Percy Liang
Collaborators: Cody Coleman, Stephen Mussmann, Baharan Mirzasoleiman
Publications:
- Selection via Proxy: Efficient Data Selection for Deep Learning
C. Coleman, C. Yeh, S. Mussmann, B. Mirzasoleiman, P. Bailis, P. Liang, J. Leskovec, and M. Zaharia
ICLR 2020 - Selection via Proxy: Increasing the Computational Efficiency of Deep Active Learning
C. Coleman, C. Yeh, S. Mussmann, B. Mirzasoleiman, P. Bailis, P. Liang, J. Leskovec, and M. Zaharia
ICLR 2020, Practical Machine Learning for Developing Countries Workshop
In both active learning and core-set selection settings, our “selection via proxy” approach uses a smaller proxy model to select data for a larger target model.
Nighttime light satellite imagery provides valuable information about economic development.
Deep learning for understanding economic well-being in Africa from publicly available satellite imagery
Stanford University, Sustainability and AI Lab, Summer 2017 - 2020
Accurate and comprehensive measurements of economic well-being are fundamental inputs into both research and policy, but such measures are unavailable at a local level in many parts of the world. We train deep learning models to predict survey-based estimates of asset wealth across ~20,000 African villages from publicly-available multispectral daytime and nightlight satellite imagery with broad temporal and spatial coverage. Models are able to explain 70% of the variation in ground-measured village wealth in countries where the model was not trained, outperforming previous benchmarks from high-resolution imagery. Comparison with independent wealth measurements from censuses suggests that errors in satellite estimates are comparable to errors in existing ground data. Validating estimates of temporal changes in wealth across ~1,500 villages is also hampered by noise in training data, but district-aggregated satellite-based estimates explain up to 50% of the variation in ground-estimated changes in wealth over time, with daytime imagery particularly useful in this task. We quantitatively demonstrate the utility of satellite-based estimates for research and policy, and demonstrate their scalability by creating a wealth map for Africa’s most populous country.
Mentors: Prof. Stefano Ermon, Prof. Marshall Burke, Prof. David Lobell
Collaborators: Anthony Perez, Anne Driscoll, George Azzari, Zhongyi Tang
Publications:
- Using publicly available satellite imagery and deep learning to understand economic well-being in Africa
C. Yeh*, A. Perez*, A. Driscoll, G. Azzari, Z. Tang, D. Lobell, S. Ermon, and M. Burke
Nature Communications, May 2020 - Poverty Prediction with Public Landsat 7 Satellite Imagery and Machine Learning
A. Perez, C. Yeh, G. Azzari, M. Burke, D. Lobell, and S. Ermon
NIPS 2017, Workshop on Machine Learning for the Developing World - Deep learning for understanding economic well-being in Africa from publicly available satellite imagery
C. Yeh, A. Perez, A. Driscoll, G. Azzari, Z. Tang, D. Lobell, S. Ermon, and M. Burke
NeurIPS 2020, Workshop on Machine Learning for Economic Policy
Nighttime light satellite imagery provides valuable information about economic development.

Estimated stereo disparity map from our model on the “Art” dataset from the Middlebury Stereo Vision Page.
Conditional Random Fields for Dense Stereo Matching
UC Irvine, Summer 2012 - Summer 2014
Various algorithms have been developed over the past two decades for solving the stereo correspondence problem, which is defined as the identification of the offset or disparity of an object in a pair of stereo images. Recent work has shown that conditional random fields (CRFs) have the potential to be faster and more accurate than traditional local matching algorithms. The canonical CRF for solving dense stereo matching problems uses a basic energy function that accounts for both local intensity matching and smoothness costs. Traditionally, the smoothness term relies on a binary Potts Model which fails to assign different costs to different disparities. In this paper, we extend the smoothness term in the energy function to be more robust. Specifically, we explore using a logarithmic function modulated by discrete edge gradient bins and binary edge detection features. The logarithmic function is able to distinguish between different disparities and therefore assign more appropriate costs. Our results suggest that our algorithm exceeds the performance of the traditional smoothness term based on a Potts Model. However, further optimization in our CRF evaluation process is necessary to achieve real-time outputs.
Mentor: Prof. Alex Ihler
Presented at 2013 Southern California Conference for Undergraduate Research (SCCUR) at Whittier College, CA.
Slides PresentationEstimated stereo disparity map from our model on the “Art” dataset from the Middlebury Stereo Vision Page.

Foam fractionation of a dilute solution of bovine lactoferrin into a glass beaker.
Effect of Aging on the Foam Fractionation of Lactoferrin
Caltech, Summer 2011
Foam fractionation is an inexpensive and simple technique for concentrating proteins. The foamability of a protein can drastically change with the age of the protein. The foamability of solutions created from ten year old bovine lactoferrin (bLF) protein was investigated with varying concentration protein, air flow velocity, and the pH of the solution. The results suggest the foamability of the aged protein decreased to an insignificant level except at high pH with a protein concentration of 0.1 mg/mL.
Mentor: Prof. Robert Tanner, Prof. Julia Kornfield
Collaborators: Benjamin Yeh, Yuehan Huang
Presented at 43rd American Chemistry Society Western Regional Meeting, Pasadena, CA.
Foam fractionation of a dilute solution of bovine lactoferrin into a glass beaker.
Archive
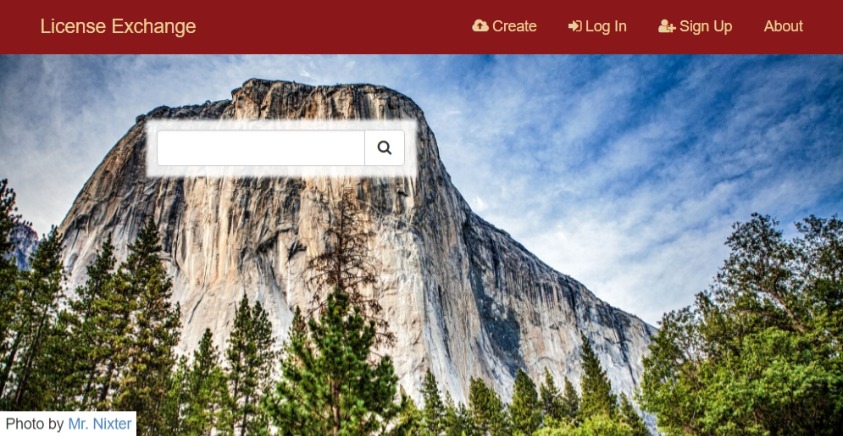
A proof-of-concept web app for simplifying the process of creating and purchasing licenses for copyrighted photos and images.
Photo Licensing Platform
Stanford University, September 2015 - June 2019
Millions of copyrighted photographs and other visual works are uploaded to the Internet daily without permission from copyright owners. In democratizing the creation and distribution of visual works, digital technologies have also transformed the landscape that effectively defines creators’ rights and consumers’ ability to track ownership information. The Stanford Law School and U.S. Copyright Office sought to address the limited licensing options and high transaction costs of existing solutions which act as barriers to lawful, licensed uses of photographs or other images.
Through Stanford Code the Change, I led a student team to create a prototype web application that simplifies the process of creating and purchasing licenses for copyrighted photos and images. For this project, I used Python, Flask, and SQL, and then deployed the app to Heroku. Our proof-of-concept web app was included as part of a report submitted to the U.S. Copyright Office.
Mentors: Prof. Paul Goldstein, Luciana Herman
Publication: A. Itai, S. Yadav, W. Zhong, L. Zhu, C. Yeh, E. Shayer, R. Barcelo, T. Liu, H. Stoyanov, P. Goldstein, L. Herman, and A. Terra, “A Low-Cost Digital Licensing Platform for Photographs: Documentation for a Prototype,” Stanford Law School Law and Policy Lab, Stanford, CA, USA, Tech. Rep., Jun. 2017. [Online]. Available: https://law.stanford.edu/publications/a-low-cost-digital-licensing-platform-for-photographs-documentation-for-a-prototype/.
Demo Report CodeA proof-of-concept web app for simplifying the process of creating and purchasing licenses for copyrighted photos and images.
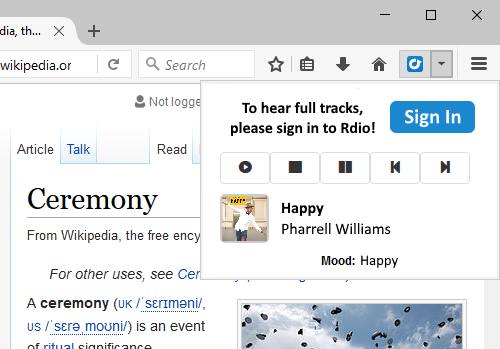
Mood Music Firefox Add-on
HackUCI Hackathon, May 2014, Top 10 Hacks and Best Rdio Hack
Mood Music was a Firefox add-on that provided users with content-relevant music that reflected the mood of the websites they visit. It used a combination of text-extraction through Diffbot, natural language processing of mood, and integration with the Rdio API to create this Firefox add-on. The inspiration behind this project was to alleviate the burden of finding good music during a user’s browsing experience.
Code Project Profile Presentation